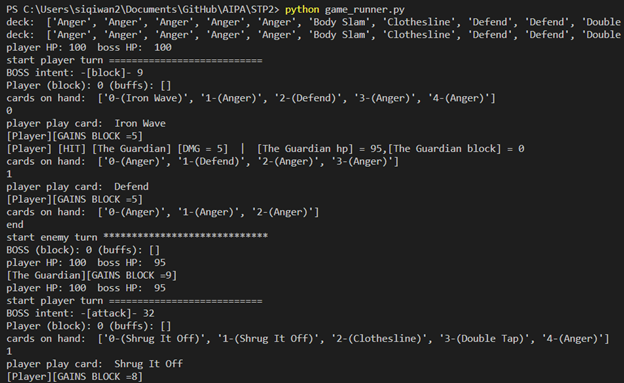
As the title suggests, this week involved a lot of experiments. The bad news is that the AI is still not close to performing optimally. We have not been able to achieve convergence in any of our experimental setups yet. However, on the positive side, we are getting closer to having a graphical interface for playing the game (one boss fight of Slay the Spire). Once this is up, we can send this out to others to test and it can help us visualize how the AI is playing our game. We are adding a replay and recording functionality into the graphical interface to achieve this. Additionally, we identified a few bugs in our game and dedicated some time to fix them as well.
Experiments with the AI
Reward Calculation Modifications
The week started with us making an important change to the AI which involved updating the reward function to manually calculate the rewards of certain cards that involve buffs (Flex, Double Tap, Disarm, Clothesline) and a couple of block cards (Defend, Shrug It Off, Iron Wave). There is a base positive reward for every point of damage done. Since these cards do not deal damage directly, it makes sense to calculate through backtracking their effectiveness.
- Flex – Playing the flex card gains reward equal to 50% of damage done by attacks played after it in the same turn. This provides an incentive to play it as early as possible. ‘50%’ sure seems high but keep in mind that Flex is a zero cost card hence the value obtained from this card is quite high (thinking about value in terms of damage/energy use).
- Double Tap – Gains reward equal to 50% of the damage dealt by the next attack played.
- Disarm – Gains reward proportional to the instances of boss damage (throughout the remainder of the game) after this card was played.
- Clothesline – Gains reward proportional to the amount of boss damage inflicted on the player in the next two turns after this card has been played.
- Defend / Shrug It Off / Iron Wave – Gains reward proportional to the amount of block used (calculated by looking at the next boss turn after playing this card). Block used is the actual block value that mitigated damage from the boss.
These reward modifications did not yield any favorable results at first glance which led us to drop them completely in successful experiments. However, we do think that the code used to do these reward modifications can be useful sometime in the future since it is a good way for us to calculate a card’s effectiveness.
Choosing Action Functionality
The next big thing that we tried this week involved modifying the way the actions were being chosen out of the array of q-values generated by the AI prediction process.
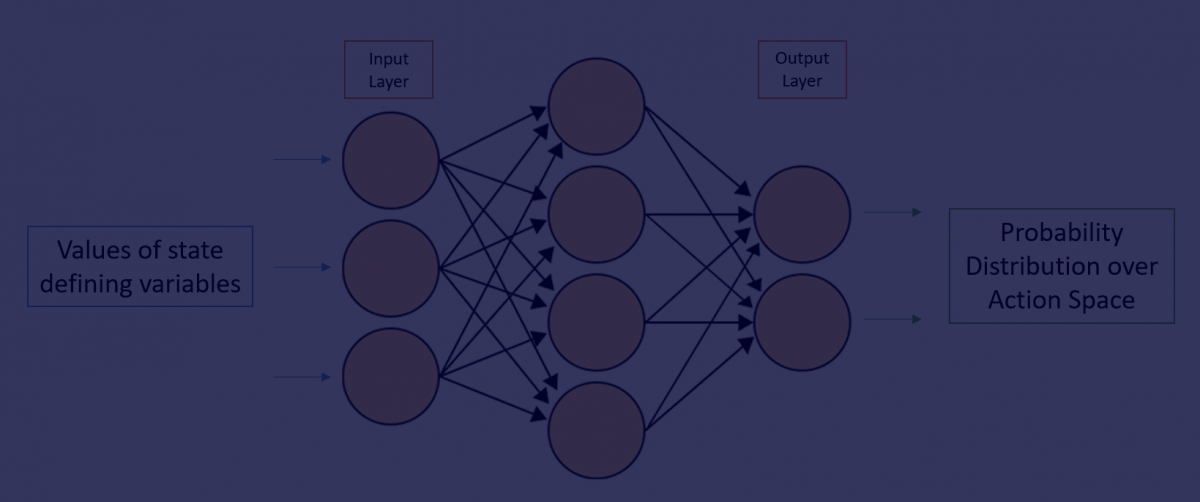
Earlier, the way of choosing the best action was to look at the predicted q-values for each card and then choose the card with the highest q-value AND was playable. One of the reasons this could be a potential problem is that the neural network is unaware of this mechanism for the choice of cards and hence it makes predictions believing that all cards are available for it to play. Logically there is an obvious flaw here. However, this effect is even more pronounced when considering the Q-Learning rule for estimating reward ( q(s,a) = reward + max a’ q(s’,a’) ). In words, the equation states that the expected reward from taking action a (playing a card) in state s (the current game state) is equal to the immediate reward from playing the card added to the maximum q-value possible for the next state. Hence, when the AI tries to predict q-values, it assumes that even in the next state, all cards are available to play. This has an inflating effect on the q-values and we have seen q-values accelerating to very high numbers.
To fix this, we now force the neural network to choose an action that is playable in the given state. We do this by giving a negative reward when the neural network attributes the highest q-value to a card that is unplayable in the given state. By doing this, the neural network is forced to pick a card that is playable. This has its own set of challenges but for now we are experimenting more in this direction.
Curse of Dimensionality (High Number Of States)
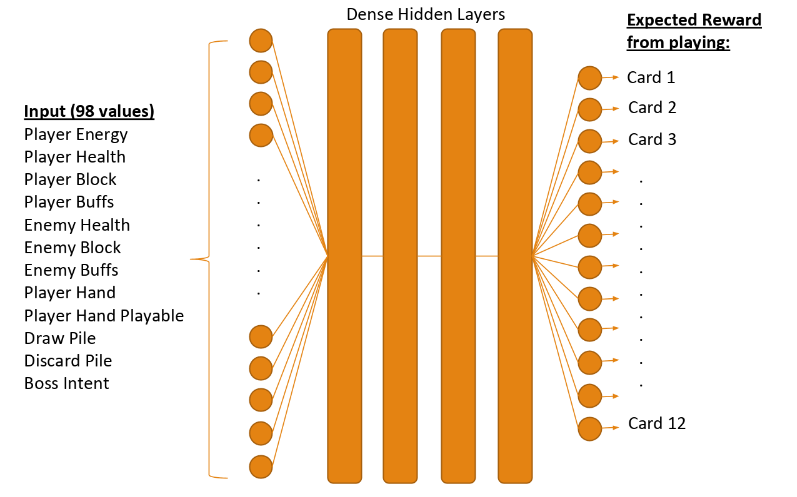
Although we are breaking down the game state into a few variables (around 100) with discrete values, the complexity of this task has a lot to do with the high number of possible states. Right now we know that there two things for sure:
- AI Agent is unable to find the best strategy to play the game
- AI Agent is unable to optimize the card play order in each turn
One of the reasons for this could be that it will take a high number of games for the AI to visit enough different states to converge. Right now, it takes about an hour to play 1000 games (each game has multiple turns and each turn has multiple card play steps).
One of the things that we are looking at right now is feature engineering. Is there a clever way to extract important information from the game state and represent it in a fewer number of states? The following is what we are looking at:
- Generalize card states by changing different cards to only genre of cards (Card’s name → Genre of the cards): Instead of checking for cards on the player’s hand, we only check how many attack cards, how many block cards and how many buff cards are on player’s hand.
- Player/Boss Buffs: Maybe this does not impact the game state too much and we can remove this altogether.
Unity Front End
Last week we built a unity front-end system which can only render a static scene. Since animation is so important for players to know what is happening, we added animations to our front end this week!
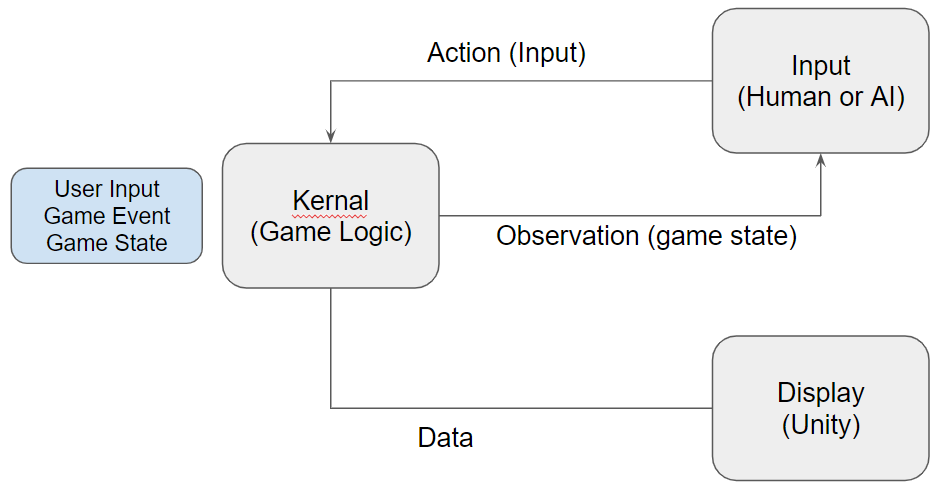
Challenges
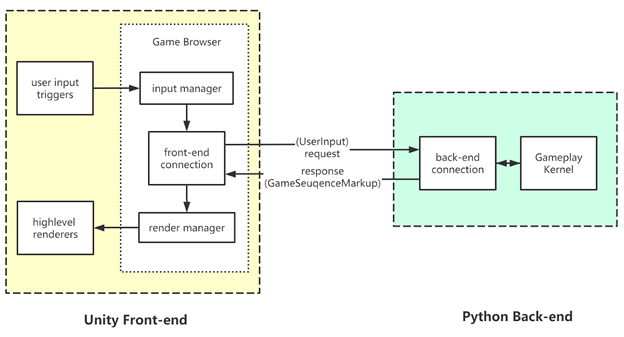
In a normal unity game, adding animation is easy since we can easily get references to all gameobject instances we want for animations. But since our game is running in python, all the object instances are stored in python runtime. An object instance sharing mechanism is hard to fit into our current request/response architecture between C#/C++.
Solution
We extended our “markup-language” to support animation. All the markups in one “game sequence markup file” share the same ID space, so they can find instance by those ID. The flow of this is shown below.
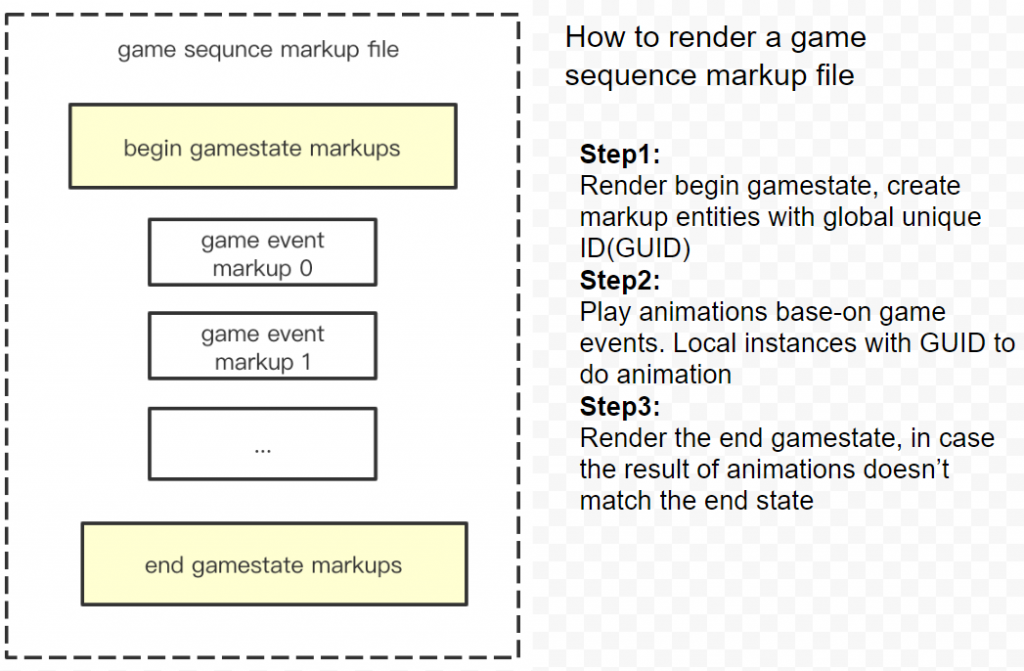
Playback System in Unity
As mentioned in the introduction above, we need a playback system in Unity in order to watch replays of games played by the AI (or humans). This tool can be incredible useful to us because:
- Store valuable information permanently : Previously we didn’t have efficient ways to store how AI/players play the game but with this system, we can store records as along as we version them and have backward compatibility.
- Clear graphical visualization : Even a single minute of AI’s gameplay generates hundreds of lines of logs which are hard to read. With graphical interface, life would be easier in evaluating what the AI is doing.
Playback Tool based on Current Architecture
This week we implemented a playback tool for the reasons cited above that is completely compatible with our current architecture. This includes:
- Font-Backed Rendering System which completely relies on the game data in markup files.
- Mechanism to Encode Gameplay Data into markup files.
- We store the data generated during runtime, and use the same Unity based rendering system to replay it.
Refactoring the Data Management Module
As part of integrating the python gameplay system with Unity rendering and the replay mechanism, we also implemented a database module to handle game data drawn from markup files. The following are some reasons why we needed to do this:
- Easier for developers to configure and modify data. This is in preparation of the design tools that we are looking to build.
- Decoupling data from gameplay is one of the most important aspects of our original design
- Preparation for game application builds
The following design considers support for multiple games versions such that each game version’s data is isolated from others. Each game supports multiple decks, and its own rule sets and card set.
The following is a brief description of what the database module handbook looks like:

Bug Fixes
We identified a few bugs this week during manual playtests and AI training. In the previous version, the boss transformed from offensive mode to defensive mode only when it is attacked by more than 30 damages in one round. In the real Slay the Spire, the damage dealt to the enemy for transformation is accumulated since the last transformation.
In order to fix this, we had to take another look at our game flow and make some changes to it. The following is a representation of how our (cleaned up) current game loop looks like:
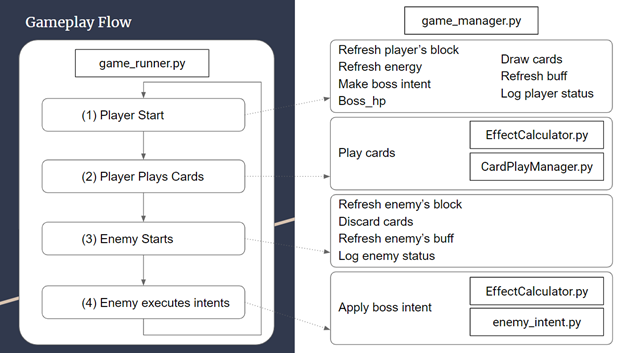
Although the AI training is still not yielding favorable results, we are learning a lot about the application of reinforcement learning to strategy games. It will surely be fun to watch the AI play in the coming week. We can then judge to see how smart it is!